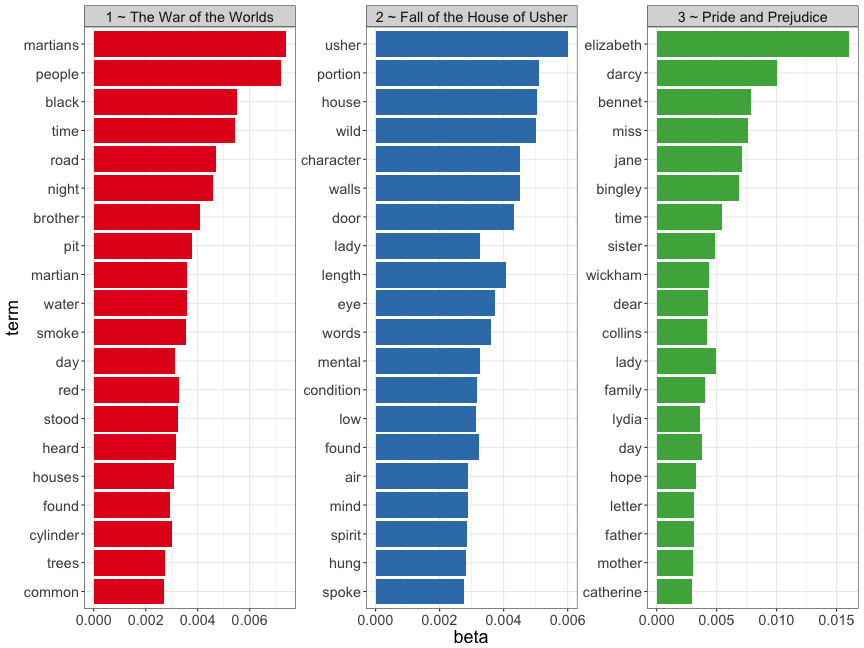
For this topic modeling analysis, three works were analyzed: Pride and Prejudice by Jane Austen, The Fall of the House of Usher by Edgar Allan Poe and The War of the Worlds by H.G. Wells. Since each work has a distinct genre and explores specific themes, these three works were apt.
Pride and Prejudice charts character development of the Bennet daughters, especially Elizabeth Bennet, exploring themes like love, marriage, social structures, wealth and class. The Fall of the House of Usher sketches a Gothic, haunted house, exploring themes like isolation, fear and the supernatural. The War of the Worlds is a science fiction tale of humans' interaction and conflicts with extraterrestrial life, exploring themes like warfare, conflict, technology, fear and otherness.
Import packages
library(gutenbergr)
library(tidytext)
library(topicmodels)
library(dplyr)
library(ggplot2)
Retrieve text from Project Gutenberg
gutenberg_works(title == "Pride and Prejudice")
## # A tibble: 1 x 8
## gutenberg_id title author gutenberg_autho… language gutenberg_bookshe…
## <int> <chr> <chr> <int> <chr> <chr>
## 1 1342 Pride … Auste… 68 en Best Books Ever L…
## # ... with 2 more variables: rights <chr>, has_text <lgl>
gutenberg_works(title == "The Fall of the House of Usher")
## # A tibble: 1 x 8
## gutenberg_id title author gutenberg_autho… language gutenberg_books…
## <int> <chr> <chr> <int> <chr> <chr>
## 1 932 The Fal… Poe, E… 481 en Movie Books
## # ... with 2 more variables: rights <chr>, has_text <lgl>
gutenberg_works(title == "The War of the Worlds")
## # A tibble: 1 x 8
## gutenberg_id title author gutenberg_autho… language gutenberg_books…
## <int> <chr> <chr> <int> <chr> <chr>
## 1 36 The Wa… Wells, … 30 en Movie Books/Sci…
## # ... with 2 more variables: rights <chr>, has_text <lgl>
literature <- gutenberg_download(c(1342, 932, 36), meta_fields = "title") # passing gutenberg_id
head(literature, 15)
## # A tibble: 15 x 3
## gutenberg_id text title
## <int> <chr> <chr>
## 1 36 The War of the Worlds The War of the…
## 2 36 "" The War of the…
## 3 36 by H. G. Wells [1898] The War of the…
## 4 36 "" The War of the…
## 5 36 "" The War of the…
## 6 36 " But who shall dwell in these worlds… The War of the…
## 7 36 " inhabited? . . . Are we or they … The War of the…
## 8 36 " World? . . . And how are all thi… The War of the…
## 9 36 " KEPLER (quoted in The Anatomy … The War of the…
## 10 36 "" The War of the…
## 11 36 "" The War of the…
## 12 36 "" The War of the…
## 13 36 BOOK ONE The War of the…
## 14 36 "" The War of the…
## 15 36 THE COMING OF THE MARTIANS The War of the…
Tokenize text
tokenize <- literature %>% unnest_tokens(word, text)
head(tokenize)
## # A tibble: 6 x 3
## gutenberg_id title word
## <int> <chr> <chr>
## 1 36 The War of the Worlds the
## 2 36 The War of the Worlds war
## 3 36 The War of the Worlds of
## 4 36 The War of the Worlds the
## 5 36 The War of the Worlds worlds
## 6 36 The War of the Worlds by
Remove stop words
tokenize_stop <- tokenize %>%
anti_join(stop_words, by = "word") %>%
dplyr::count(title, word, sort = TRUE)
Cast text to Document Term Matrix (DTM) and applying Latent Dirichlet Allocation Model (LDA)
dtm <- tokenize_stop %>% cast_dtm(title, word, n) # casting tokenized text in Document Term Matrix (DTM)
LDM_model <- LDA(dtm, k = 3, control = list(seed = 1234)) # selecting k = 3 for three texts
result <- tidy(LDM_model, matrix = "beta")
Retrieve top 20 words from each topic
top_20_words <- result %>%
group_by(topic) %>%
top_n(20, beta) %>%
ungroup() %>%
arrange(topic, -beta) %>%
mutate(term = reorder(term, beta))
Plot top 20 words
top_20_words$topic <- factor(top_20_words$topic)
levels(top_20_words$topic)
top_20_words$topic <- plyr::revalue(top_20_words$topic, replace = c("1" = "1 ~ The War of the Worlds",
"2" = "2 ~ Fall of the House of Usher",
"3" = "3 ~ Pride and Prejudice"))
ggplot(top_20_words, aes(term, beta, fill = topic)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") + theme_bw() +
coord_flip() + scale_fill_brewer(palette = "Set1") + theme(text = element_text(size = 18))