Following post shows an overview of Random Forests using the Wisconsin Breast Cancer Dataset, from UCI Machine Learning Repository. Random Forests are a type of ensemble learning methods that learn from training number of individual decision trees, thereby reducing model variability and improving performance.
Wisconsin Breast Cancer Data, collected from the University of Wisconsin Hospitals, Madison from Dr. William H. Wolberg, is composed of 11 cytological attributes computed from digitized images of a fine needle aspirate (FNA) of a breast mass. Collected cell attributes include clump thickness, uniformity of cell size and cell shape, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatin, normal nucleoli and mitoses. Features are used to differentiate between benign and malignant samples, as defined by the Class predictor. For further details about feature definition and data collection, see publication.
Import packages
library(randomForest)
library(caret)
Reading and Cleaning Wisconsin Breast Cancer Dataset from UCI Machine Learning Repository
breast_cancer <- read.csv("https://raw.githubusercontent.com/azkajavaid/BreastCancerWisconsinData-UCI/master/BreastCancerData.txt?token=ANkFlyu6ncAg-xoOxqhgB6wSw0GRnuBOks5atcg2wA%3D%3D")
colnames(breast_cancer) <- c("Code", "ClumpThickness", "UniformCellSize", "UniformCellShape", "MarginalAdhesion", "EpithelialCellSize", "BareNuclei", "BlandChromatin", "NormalNucleoli", "Mitoses", "Class")
breast_cancer$Class <- as.character(breast_cancer$Class)
breast_cancer$Class <- revalue(breast_cancer$Class, c("2" = "Benign", "4" = "Malignant"))
breast_cancer$Class <- as.factor(breast_cancer$Class)
breast_cancer <- breast_cancer[!(breast_cancer$BareNuclei == "?"),] # dropping all observations with BareNuclei value of "?"
breast_cancer$BareNuclei <- as.integer(breast_cancer$BareNuclei)
Split data in training and test sets
set.seed(90)
n <- nrow(breast_cancer)
index = sample(1:n, size = round(0.75*n), replace = FALSE)
train = breast_cancer[index, ]
test = breast_cancer[-index, ]
paste("Observations in training data: ", nrow(train), sep = "")
## [1] "Observations in training data: 512"
paste("Observations in testing data: ", nrow(test), sep = "")
## [1] "Observations in testing data: 170"
Fit Random Forest model, predicting Class
forest_model <- randomForest(Class ~ ., data = train)
forest_model
##
## Call:
## randomForest(formula = Class ~ ., data = train)
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 3
##
## OOB estimate of error rate: 2.93%
## Confusion matrix:
## Benign Malignant class.error
## Benign 320 10 0.03030303
## Malignant 5 177 0.02747253
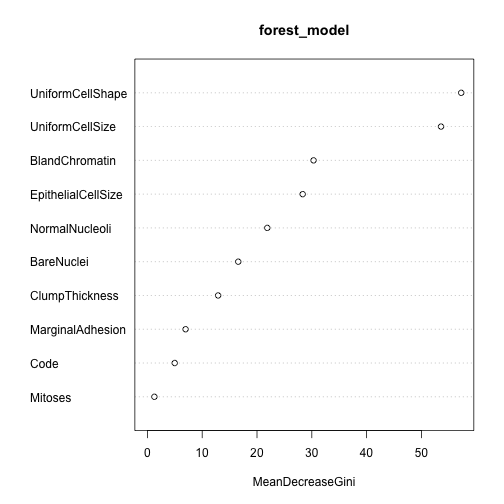
Calculate variable importance
## Overall
## Code 4.990360
## ClumpThickness 12.905821
## UniformCellSize 53.571084
## UniformCellShape 57.252280
## MarginalAdhesion 6.969599
## EpithelialCellSize 28.332916
## BareNuclei 16.577294
## BlandChromatin 30.316033
## NormalNucleoli 21.874285
## Mitoses 1.278367
Calculate accuracy for Class predictions on test data
predictions <- predict(forest_model, test)
forest_tab <- base::table(predictions, test$Class)
round(sum(diag(forest_tab))/sum(forest_tab), 3)